Data Visualization
“Veri görselleştirme, karmaşık veri kümelerini anlaşılır ve etkileşimli görsel formatlarda sunarak, bilgiyi daha etkili bir şekilde iletmeyi sağlar. Bu yaklaşım, veri analizini herkes için daha erişilebilir ve anlaması kolay hale getirir, böylece karar verme süreçlerini destekler.”
Welcome to “Bike Demand Visualization Project” which is the capstone project of Data Visualization Lessons . As you know recently, free or affordable access to bicycles has been provided for short-distance trips in an urban area as an alternative to motorized public transport or private vehicles. Thus, it is aimed to reduce traffic congestion, noise and air pollution.
The aim of this project is to reveal the current patterns in the data by showing the historical data of London bike shares with visualization tools.
This will allow us to X-ray the data as part of the EDA process before setting up a machine learning model.
Determines
Features
– timestamp – timestamp field for grouping the data
– cnt – the count of a new bike shares
– t1 – real temperature in C
– t2 – temperature in C “feels like”
– hum – humidity in percentage
– wind_speed – wind speed in km/h
– weather_code – category of the weather
– is_holiday – boolean field – 1 holiday / 0 non holiday
– is_weekend – boolean field – 1 if the day is weekend
– season – category field meteorological seasons: 0-spring ; 1-summer; 2-fall; 3-winter.
“weather_code” category description:
– 1 = Clear ; mostly clear but have some values with haze/fog/patches of fog/ fog in vicinity
– 2 = scattered clouds / few clouds
– 3 = Broken clouds
– 4 = Cloudy
– 7 = Rain/ light Rain shower/ Light rain
– 10 = rain with thunderstorm
– 26 = snowfall
– 94 = Freezing Fog
Initially, the task of discovering data will be waiting for you as always. Recognize features, detect missing values, outliers etc. Review the data from various angles in different time breakdowns. For example, visualize the distribution of bike shares by day of the week. With this graph, you will be able to easily observe and make inferences how people’s behavior changes daily. Likewise, you can make hourly, monthly, seasonally etc. analyzes. In addition, you can analyze correlation of variables with a heatmap.
import pandas as pd
import numpy as np
#import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")df = pd.read_csv("store_sharing.csv")
dfdf.info() #no null
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 17414 entries, 0 to 17413
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 timestamp 17414 non-null object
1 cnt 17414 non-null int64
2 t1 17414 non-null float64
3 t2 17414 non-null float64
4 hum 17414 non-null float64
5 wind_speed 17414 non-null float64
6 weather_code 17414 non-null float64
7 is_holiday 17414 non-null float64
8 is_weekend 17414 non-null float64
9 season 17414 non-null float64
dtypes: float64(8), int64(1), object(1)
memory usage: 1.3+ MBdf.drop_duplicates() df.isna().sum()
timestamp 0
cnt 0
t1 0
t2 0
hum 0
wind_speed 0
weather_code 0
is_holiday 0
is_weekend 0
season 0
dtype: int64df.notnull().sum()
timestamp 17414
cnt 17414
t1 17414
t2 17414
hum 17414
wind_speed 17414
weather_code 17414
is_holiday 17414
is_weekend 17414
season 17414
dtype: int64
1.1 CODING TASK #1. PLOT PIE CHART USING MATPLOTLIB
- The plot method on Pandas Series and DataFrames is just a simple wrapper around plt.plot():
- Define a Pandas Dataframe with all crypto allocation in a given portfolio
- Note that total sum = 100%
- Use matplotlib to plot a pie chart
import pandas as pd
import numpy as np
#import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")PRACTICE OPPORTUNITY #1:
- Assume that you became bullish on XRP and decided to allocate 60% of your assets in it. You also decided to equally divide the rest of your assets in other coins (BTC, LTC, ADA, and ETH). Change the allocations and plot the pie chart.
- Use ‘explode’ to increase the separation between XRP and the rest of the portfolio (External Research is Required)
• BTC (Bitcoin): Bitcoin’in o tarihteki fiyatını gösteren sütun.
• LTC (Litecoin): Litecoin’in o tarihteki fiyatını gösteren sütun.
• ETH (Ethereum): Ethereum’un o tarihteki fiyatını gösteren sütun.
• ADA (Cardano): Cardano’nun o tarihteki fiyatını gösteren sütun.
• XRP (Ripple): Ripple’ın o tarihteki fiyatını gösteren sütun.
crypto_df = pd.DataFrame(data = {'allocation %':[10, 10, 10, 60, 10]}, index = ['BTC', 'ETH', 'LTC', 'XRP', 'ADA'])
crypto_df
allocation %
BTC 10
ETH 10
LTC 10
XRP 60
ADA 10plt.figure(figsize = (10, 8))
mylabels = ['BTC', 'ETH', 'LTC', 'XRP', 'ADA']
myexplode = [0, 0, 0, 0.12, 0]
plt.pie(crypto_df['allocation %'], labels = mylabels, labeldistance = 0.7 , autopct='%1.1f%%', explode = myexplode, shadow = True)
plt.title('Cryptocurrency Allocations')
plt.show()
Bu portföy, yatırımcının büyük bir güvenle XRP’ye yatırım yaptığını ve portföyünün çoğunu (%60) bu kripto para birimine tahsis ettiğini gösteriyor. Diğer dört kripto para birimi eşit ağırlıklara sahip ve her biri portföyün %10’unu temsil ediyor. Bu, yatırımcının riski bir ölçüde çeşitlendirmeye çalıştığını ancak hala belirli bir varlık (XRP) üzerinde büyük bir odaklanma olduğunu gösterir.
Portföy, yüksek risk toleransına sahip yatırımcılar için uygundur, çünkü büyük bir bahis XRP’ye yapılmıştır. Ancak, tek bir varlığa yoğunlaşma, o varlığın performansına bağlı olarak yüksek bir risk taşır. Çeşitlilik ve risk yönetimi önemlidir, bu nedenle bu strateji, belirli bir varlıkta yüksek bir maruziyet isteyen yatırımcılar için uygun olabilir, ancak çeşitlilik arayanlar için dengesiz görünebilir.
Kripto para birimlerinin piyasa koşulları ve performansındaki dalgalanmalar, portföyün etkinliğini etkileyebilir. Bu nedenle, yatırımcılar sürekli olarak piyasa gelişmelerini takip etmeli ve potansiyel riskleri gözden geçirmelidir.
1.2 CODING TASK #2. PLOT SINGLE & MULTIPLE LINE PLOTS USING MATPLOTLIB
- Use Pandas read_csv to read crypto_daily_prices (BTC, ETH, and LTC)
- Use matplotlib on the Pandas DataFrame to plot the data
investments_df = pd.read_csv('crypto_daily_prices.csv')
investments_df
Date BTC ETH ADA
0 9/17/2014 457.334015 NaN NaN
1 9/18/2014 424.440002 NaN NaN
2 9/19/2014 394.795990 NaN NaN
3 9/20/2014 408.903992 NaN NaN
4 9/21/2014 398.821014 NaN NaN
... ... ... ... ...
2828 6/15/2022 22572.839840 1233.206421 0.533296
2829 6/16/2022 20381.650390 1067.730713 0.475022
2830 6/17/2022 20471.482420 1086.519287 0.487392
2831 6/18/2022 19017.642580 993.636780 0.456182
2832 6/19/2022 19488.886720 1040.510254 0.464109
2833 rows × 4 columnsİlk beş kayıt incelendiğinde, Ethereum (ETH) ve Cardano (ADA) için verilerin başlangıçta mevcut olmadığını görüyoruz; bu, muhtemelen bu kripto paraların o tarihlerde henüz piyasada olmadığını veya veri setinin o tarihlerde bu paralar için veri toplamadığını gösteriyor. Bitcoin (BTC) için ise 17 Eylül 2014 tarihinden itibaren fiyat verileri bulunuyor.
Bu veri seti, analizler ve kripto para piyasası trendlerini incelemek için kullanılabilir. Örneğin, belirli bir zaman aralığında kripto para fiyatlarındaki değişimleri gözlemleyebilir, farklı kripto paraların fiyat hareketlerini karşılaştırabilir veya uzun vadeli fiyat trendlerini analiz edebilirsiniz
investments_df.isnull().sum()[investments_df.isnull().sum()>0]
ETH 1149
ADA 1149
dtype: int64investments_df.fillna(0, inplace=True)investments_df.isnull().sum()[investments_df.isnull().sum()>0]
Series([], dtype: int64)
investments_df.isnull().sum()
Date 0
BTC 0
ETH 0
ADA 0
dtype: int64investments_df['Date'] = pd.to_datetime(investments_df['Date'])
investments_df['Year'] = investments_df['Date'].dt.year
investments_df['Month'] = investments_df['Date'].dt.month
investments_df
Date BTC ETH ADA Year Month
0 2014-09-17 457.334015 0.000000 0.000000 2014 9
1 2014-09-18 424.440002 0.000000 0.000000 2014 9
2 2014-09-19 394.795990 0.000000 0.000000 2014 9
3 2014-09-20 408.903992 0.000000 0.000000 2014 9
4 2014-09-21 398.821014 0.000000 0.000000 2014 9
... ... ... ... ... ... ...
2828 2022-06-15 22572.839840 1233.206421 0.533296 2022 6
2829 2022-06-16 20381.650390 1067.730713 0.475022 2022 6
2830 2022-06-17 20471.482420 1086.519287 0.487392 2022 6
2831 2022-06-18 19017.642580 993.636780 0.456182 2022 6
2832 2022-06-19 19488.886720 1040.510254 0.464109 2022 6
2833 rows × 6 columnsinvestments_df.dtypes
Date datetime64[ns]
BTC float64
ETH float64
ADA float64
Year int32
Month int32
dtype: object
plt.figure(figsize = (8, 5))
investments_df.plot(x = "Date",y = "BTC" )
plt.title("Change of BTC over Year ")
plt.show()
plt.figure(figsize =plt.figure(figsize = (8, 5))
investments_df.plot(x = "Date",y = "BTC" )
plt.title("Change of BTC over Year ")
plt.show()

import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")1- Warnings import Nedir?
Python’da import warnings ifadesi, Python’un uyarı (warnings) sistemini programınıza dahil etmek için kullanılır.
warnings.filterwarnings(“ignore”) ifadesi ise, belirli uyarıları bastırmak (yani görmezden gelmek) için kullanılır.
Bu komut verildiğinde, program çalıştırıldığında normalde çıkacak olan uyarı mesajları gösterilmez. Bu, özellikle temiz bir çıktı istediğinizde veya uyarıların önemsiz olduğunu düşündüğünüzde kullanışlı olabilir.
2 – Data Seti İçeriye Alma
- sns.get_dataset_names()
- DATA_ADI = sns.load_dataset(“DATA_ADI”)
3 – Data Setini İçeriye Aldıktan Sonra Başlıca Kullanmamız Gereken Fonksiyonlar
- DATA_ADI.head(5): Veri setinin ilk 5 satırını döndürür.
- DATA_ADI.sample(5): Veri setinden rastgele 5 satırı döndürür.
- DATA_ADI.tail(): Veri setinin son 5 satırını döndürür (eğer sayı belirtilmezse varsayılan olarak 5 satır alır).
- DATA_ADI.shape: Veri setinin satır ve sütun sayısını bir tuple olarak döndürür.
- DATA_ADI.info(): Veri seti hakkında dizin, sütun isimleri, veri tipleri, non-null değer sayıları ve hafıza kullanımı gibi temel bilgiler sağlar.
- DATA_ADI.describe().T: Sayısal sütunlar için temel istatistiksel özetleri (sayım, ortalama, standart sapma, min/max değerler, ve yüzdelik dilimler) transpoze edilmiş bir tablo olarak döndürür.

4 – Seaborn Kütüphanesindeki Data Setlerine Nasıl Ulaşırım?
“sns.get_dataset_names()” fonksiyonu, Python’da seaborn kütüphanesinde yer alan ve seaborn tarafından sağlanan örnek veri setlerinin isimlerini bir liste olarak döndüren bir fonksiyondur.
sns.get_dataset_names()
['anagrams',
'anscombe',
'attention',
'brain_networks',
'car_crashes',
'diamonds',
'dots',
'dowjones',
'exercise',
'flights',
'fmri',
'geyser',
'glue',
'healthexp',
'iris',
'mpg',
'penguins',
'planets',
'seaice',
'taxis',
'tips',
'titanic']tips = sns.load_dataset("tips")Seaborn kütüphanesinde bulunan ‘tips’ veri seti, restoranlarda bahşiş verme davranışı ile ilgili verileri içerir. Bu veri seti, farklı öğünlerde, farklı günlerde ve farklı cinsiyet/kişi sayıları için alınan bahşiş miktarlarını içermektedir. Aşağıda, bu veri setindeki sütunların açıklamaları bulunmaktadır:
- total_bill: Toplam hesap miktarı (ABD doları cinsinden).
- tip: Bahşiş miktarı (ABD doları cinsinden).
- sex: Hesabı ödeyen kişinin cinsiyeti (Erkek/Kadın).
- smoker: Grubun içinde sigara içen olup olmadığı (Evet/Hayır).
- day: Hesabın ödendiği gün (Perşembe, Cuma, Cumartesi, Pazar).
- time: Hesabın ödendiği öğün zamanı (Öğle yemeği/Akşam yemeği).
- size: Grubun kişi sayısı. Bu veri seti, bahşiş verme alışkanlıklarını çeşitli açılardan incelemek için kullanılabilir.
tips.head(5)
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4tips.sample(5)
total_bill tip sex smoker day time size
70 12.02 1.97 Male No Sat Dinner 2
9 14.78 3.23 Male No Sun Dinner 2
88 24.71 5.85 Male No Thur Lunch 2
191 19.81 4.19 Female Yes Thur Lunch 2
195 7.56 1.44 Male No Thur Lunch 2tips.tail()
total_bill tip sex smoker day time size
239 29.03 5.92 Male No Sat Dinner 3
240 27.18 2.00 Female Yes Sat Dinner 2
241 22.67 2.00 Male Yes Sat Dinner 2
242 17.82 1.75 Male No Sat Dinner 2
243 18.78 3.00 Female No Thur Dinner 2tips.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 244 entries, 0 to 243
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 total_bill 244 non-null float64
1 tip 244 non-null float64
2 sex 244 non-null category
3 smoker 244 non-null category
4 day 244 non-null category
5 time 244 non-null category
6 size 244 non-null int64
dtypes: category(4), float64(2), int64(1)
memory usage: 7.4 KBtips.describe().T
count mean std min 25% 50% 75% max
total_bill 244.0 19.785943 8.902412 3.07 13.3475 17.795 24.1275 50.81
tip 244.0 2.998279 1.383638 1.00 2.0000 2.900 3.5625 10.00
size 244.0 2.569672 0.951100 1.00 2.0000 2.000 3.0000 6.00Scatter Plot
Scatter plot, iki değişken arasındaki ilişkiyi noktalar kullanarak görselleştiren bir grafik türüdür. Bu grafik, veri noktalarının dağılımını ve değişkenler arasındaki potansiyel korelasyonu görmek için kullanışlıdır, ayrıca seaborn’un çeşitli özelleştirme seçenekleri ile renk, boyut ve stil açısından kolayca zenginleştirilebilir.
sns.scatterplot(data = tips, x = "total_bill", y = "tip")
plt.show()
**NOT: Güven Aralığı: CI : en çok kullanılan CI değerleri 95-99 dur.. Python default olarak %95 alır.
sns.regplot(data = tips, x = "total_bill", y = "tip");

!pip install matplotlib
!pip install seabornimport numpy as np
import pandas as pd
import matplotlib as mpl #bugüne özel sadece , version kontrol etmek için
import matplotlib.pyplot as plt
%matplotlib inline
#%matplotlib notebook
import warnings;
warnings.filterwarnings("ignore")print(mpl.__version__)

x = np.arange(0,10)
xy = x * 2
yplt.plot(x,y)
plt.show()
y_2 = np.arange(0,9)plt.plot(x, y_2); #eleman sayıları eşit olmadığı için hata verir
# y_2 = np.arange(0,9) # x'e karşılık gelen bir değer olmadığından
# plt.plot(x, y_2); # hata verirprint(plt.style.available)
['Solarize_Light2', '_classic_test_patch', '_mpl-gallery', '_mpl-gallery-nogrid', 'bmh', 'classic', 'dark_background', 'fast', 'fivethirtyeight', 'ggplot', 'grayscale', 'seaborn-v0_8', 'seaborn-v0_8-bright', 'seaborn-v0_8-colorblind', 'seaborn-v0_8-dark', 'seaborn-v0_8-dark-palette', 'seaborn-v0_8-darkgrid', 'seaborn-v0_8-deep', 'seaborn-v0_8-muted', 'seaborn-v0_8-notebook', 'seaborn-v0_8-paper', 'seaborn-v0_8-pastel', 'seaborn-v0_8-poster', 'seaborn-v0_8-talk', 'seaborn-v0_8-ticks', 'seaborn-v0_8-white', 'seaborn-v0_8-whitegrid', 'tableau-colorblind10']#plt.style.use("seaborn-v0_8-darkgrid")
#plt.style.use("_mpl-gallery-nogrid")
#plt.style.use("dark_background")
#plt.style.use("seaborn-v0_8-dark-palette")plt.style.use("seaborn-v0_8-darkgrid")plt.plot(x,y)
plt.show()
plt.figure(figsize=(10,5))
plt.plot(x,y)
plt.show()
Grafiklere Argüman Verme (markdown)
x = np.linspace(0, 10, 100)
x
array([ 0. , 0.1010101 , 0.2020202 , 0.3030303 , 0.4040404 ,
0.50505051, 0.60606061, 0.70707071, 0.80808081, 0.90909091,
1.01010101, 1.11111111, 1.21212121, 1.31313131, 1.41414141,
1.51515152, 1.61616162, 1.71717172, 1.81818182, 1.91919192,
2.02020202, 2.12121212, 2.22222222, 2.32323232, 2.42424242,
2.52525253, 2.62626263, 2.72727273, 2.82828283, 2.92929293,
3.03030303, 3.13131313, 3.23232323, 3.33333333, 3.43434343,
3.53535354, 3.63636364, 3.73737374, 3.83838384, 3.93939394,
4.04040404, 4.14141414, 4.24242424, 4.34343434, 4.44444444,
4.54545455, 4.64646465, 4.74747475, 4.84848485, 4.94949495,
5.05050505, 5.15151515, 5.25252525, 5.35353535, 5.45454545,
5.55555556, 5.65656566, 5.75757576, 5.85858586, 5.95959596,
6.06060606, 6.16161616, 6.26262626, 6.36363636, 6.46464646,
6.56565657, 6.66666667, 6.76767677, 6.86868687, 6.96969697,
7.07070707, 7.17171717, 7.27272727, 7.37373737, 7.47474747,
7.57575758, 7.67676768, 7.77777778, 7.87878788, 7.97979798,
8.08080808, 8.18181818, 8.28282828, 8.38383838, 8.48484848,
8.58585859, 8.68686869, 8.78787879, 8.88888889, 8.98989899,
9.09090909, 9.19191919, 9.29292929, 9.39393939, 9.49494949,
9.5959596 , 9.6969697 , 9.7979798 , 9.8989899 , 10. ])x=np.linspace(0,10,100)
y=np.sin(x)
plt.figure(figsize=(8,6))
plt.plot(x,y,"yo")
plt.show()
x=np.linspace(0,10,100)
y=np.sin(x)
plt.figure(figsize=(8,6))
plt.plot(x,y,"lightpink")
plt.show()

Katkılarından dolayı hocam Mustafa Erdogan’a teşekkür ederim.
KAYNAK:https://medium.com/academy-team/pythonda-i%CC%87nteraktif-veri-g%C3%B6rselle%C5%9Ftirme-bokeh-36775af00bd1
!pip install bokeh1- Line Plot çizimi
from bokeh.plotting import figure, show
from bokeh.io import output_notebook
# Jupyter Notebook için çıktıyı ayarlar
output_notebook()
# Veri oluşturma
x = [2, 4, 6, 8, 10]
y = [12, 14, 4, 16, 18]
# Bokeh için bir figure (şekil) oluşturur
p = figure(title='Basit Bir Cizgi Grafigi', x_axis_label='X', y_axis_label='Y')
# Çizgi grafiğini oluşturur
p.line(x, y, legend_label='Cizgi', line_width=2)
# Grafiği gösterir
show(p)
2 – Scatter Grafiği Çizimi
Şimdi, Bokeh kütüphanesini kullanarak basit bir scatter plot grafiği oluşturalım. Oluşan bu scatter grafiğinde grafiği özellşetimek için bazı parametrelerde kullanılmıştır.
# figure ölçülerini kullanarak yeni bir çizim oluşturur
p = figure(width=400, height=400)
# Grafik dışındaki yapılan özelleştirmeler
p.outline_line_width = 7
p.outline_line_alpha = 0.3
p.outline_line_color = "red"
# Veri oluşturma
x = [2, 4, 6, 8, 10]
y = [12, 8, 4, 16, 18]
# Scatter grafiğini oluşturur
r = p.circle(x, y, size=15, line_color="navy", fill_color="orange", fill_alpha=0.5)
# Grafiği gösterir
show(p)
Scatter grafiğini dilerseniz daireler ile değil kareler kullanaraktan yapabilirsiniz.
# figure ölçülerini kullanarak yeni bir çizim oluştur
p = figure(width=500, height=500)
# Grafik dışındaki yapılan özelleştirmeler
p.outline_line_width = 7
p.outline_line_alpha = 0.3
p.outline_line_color = "purple"
# Veri oluşturma
x = [2, 4, 6, 8, 10]
y = [12, 8, 4, 16, 18]
# Scatter Plot grafiğini oluştur opsiyonel olarak size, color, alpha gir
p.square(x, y, size=[10, 15, 20, 25, 30], line_color="black", color="green", alpha=0.9)
# Grafiği gösterir
show(p)
3 – Grafik Üzerinde Stil ve Düzenleme Yapma
Bokeh, grafiğinizi özelleştirmek için birçok seçenek sunmaktadır. Örneğin, akses etiketlerini, başlığı, çizgi kalınlığını ve renklerini ayarlayabilirsiniz.
# Veri oluşturma
x = [2, 4, 6, 8, 10]
y = [12, 14, 4, 16, 18]
# Çizgi grafiğini oluşturur
p.line(x, y, legend_label='Cizgi', line_width=6, line_color = 'red')
p.title.text = 'Yeni Baslık'
p.xaxis.axis_label = 'Yeni X Ekseni Etiketi'
p.yaxis.axis_label = 'Yeni Y Ekseni Etiketi'
# Grafiği gösterir
show(p)

Katkılarından dolayı hocamın Mustafa Erdogan’a teşekkür ederiz.
KAYNAK: https://medium.com/academy-team/plotly-ile-veri-g%C3%B6rselle%C5%9Ftirmede-s%C4%B1n%C4%B1r-tan%C4%B1may%C4%B1n-c2af4369cc3c
Kütüphaneleri yükleyelim
Açıklamalar:
- !pip install plotly
- !pip install dash: reaktif web uygulamaları oluşturmak için geliştirilmiştir.dash board
- !pip install wordcloud :özellikle kelime bulutu nlp alanında kullanılabilir bir kelimenin önemi için
- !pip install cufflinks :pandas kütüphanesi ile çalışabilen bir kütüphanedir.
- !pip install missingno :kayıp verileri görselleştirmek için
!pip install plotly
!pip install dash
!pip install wordcloud
!pip install cufflinks
!pip install missingnoŞimdi ise import’larımızı yapalım
NOT: Bu importları yaparken; “C:\Users\Hp\anaconda3\Lib\site-packages\paramiko\transport.py:219: CryptographyDeprecationWarning: Blowfish has been deprecated” hatası alabilirsiniz. Bu hata Blowfish şifreleme algoritmasının Cryptography kütüphanesinde artık kullanılmayacağını bildiriyor. Bu hatayı çözmek için Anaconda Terminalinde “conda update paramiko cryptography” komutunu kullanarak güncelleme yaptığınızda artık kütüphaneniz güncel bir şekilde import edilecektir.
import numpy as np
import pandas as pd
import seaborn as sns
import os
import missingno
# plotly
import plotly as py
from plotly.offline import init_notebook_mode, iplot, plot
init_notebook_mode(connected = True) #inline olarak görüntülemek için başlatıyoruz same to = %matplotlib inline
import plotly.graph_objs as go # veri görselleştirme için düşük düzey arayüz
import plotly.express as px # veri görselleştirme için üst düzey arayüz kısaca daha komplex bir görsel için daha az kod satırı
# word cloud library
from wordcloud import WordCloud
# matplotlib
import matplotlib.pyplot as plt
import cufflinks as cf #pandas kütüphanesi ile çalışabilen bir kütüphanedir.
cf.go_offline() #grafikleri offline olarak yapıyoruz
# warnings
import warnings
warnings.filterwarnings("ignore") #kod satırlarında önemsiz uyarıları görmemek için kullanıyoruz.Şimdi de örnek yapacağımız data setini yükleyelim.
Öncesinde datayı tanımlayalım tabiki. Data setimiz dünya genelindeki üniversitelerle ilgili çeşitli özellikleri ve değerlendirmeleri içeren bilgileri içermektedir. Her özellik, üniversitelerin farklı yönlerini değerlendiren kriterlere göre bilgi içerir.
Data setimiz toplamda 14 özelliği içermektedir. Bunlar;
- world_rank: Üniversitelerin dünya genelindeki sıralaması.
- university_name: Üniversitenin ismi.
- country: Üniversitenin bulunduğu ülke.
- teaching: Öğretim kalitesini belirten bir skor.
- international: Uluslararası çeşitlilik ve etkileşimi belirten bir ölçüt.
- research: Üniversitenin araştırma performansını belirten bir skor.
- citations:Üniversitenin araştırma çıktılarının alıntı sayısı veya etkisi.
- income: Üniversitenin geliri veya finansal sağlığı.
- total_score: Üniversitelerin genel performansını belirten bir skor.
- num_students:Üniversitede kayıtlı öğrenci sayısı.
- student_staff_ratio: Öğrenci başına düşen personel sayısı.
- international_students: Üniversitedeki uluslararası öğrenci yüzdesi veya sayısı.
- female_male_ratio: Kadın erkek oranı.
- year: Verinin alındığı yıl.
timesData = pd.read_csv("https://raw.githubusercontent.com/arnaudbenard/university-ranking/master/timesData.csv")
timesData.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2603 entries, 0 to 2602
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 world_rank 2603 non-null object
1 university_name 2603 non-null object
2 country 2603 non-null object
3 teaching 2603 non-null float64
4 international 2603 non-null object
5 research 2603 non-null float64
6 citations 2603 non-null float64
7 income 2603 non-null object
8 total_score 2603 non-null object
9 num_students 2544 non-null object
10 student_staff_ratio 2544 non-null float64
11 international_students 2536 non-null object
12 female_male_ratio 2370 non-null object
13 year 2603 non-null int64
dtypes: float64(4), int64(1), object(9)
memory usage: 284.8+ KBŞimdi data setimizin ilk 100 satırını seçip görselleştirme örneklerimi bu data seti üzerinden yapmak istiyorum.
df = timesData.iloc[:100, :]1 – Plotly ile Kodlama
Plotly kütüphanesinin syntax’ı diğer görsel kütüphanelere göre karmaşık gelebilir. Ancak aslında mantığı anlaşıldığında tıpkı bir boşluk dolurur gibi kod parçası oluşturabiliriz. Bunun için öncelikle plotly kütüphanesinin Figure objesini kavramak gerekmektedir. Figure objesi genellikle iki ana bileşenden oluşur. Bunlar Data ve Layout’tur.
- Data bileşeni, grafiğin çizilmesi için gereken veriyi içerirken
- Layout bileşeni grafiğin görünümü ile ilgili ayarları içermektedir.
1.0.0.1 Data:
Data bileşeni, genellikle bir veya birden fazla çizgi (trace) içerir. Her bir çizgi, Scatter, Bar, Box, Heatmap vb. olabilir ve her biri kendi özel ayarlarına sahiptir.
1.0.0.2 Layout:
Layout bileşeni, grafiğin başlığı, eksen başlıkları, ızgara çizgileri, arka plan rengi vb. gibi çeşitli stil ve formatlama ayarlarını içerir.

import plotly.graph_objects as go
# Data
trace = go.Scatter(x=[1, 2, 3, 4], y=[10, 11, 12, 13])
# Layout
layout = go.Layout(title='Basit Çizgi Grafiği', xaxis=dict(title='X Ekseni'), yaxis=dict(title='Y Ekseni'))
# Figure
fig = go.Figure(data=[trace], layout=layout)
# Çizim
fig.show()
Line Chart
Line grafik (çizgi grafiği), genellikle zamanla değişen değerleri göstermek için kullanılan bir grafik türüdür. Line grafik zamanla değişimi göstermek, trendleri belirlemek, karşılaştırmalar yapmak, öngörülerde bulunmak için de kullanılır.
Plotly kütüphanesi ile bir line chart çizdirelim. Bu kod parçası ile, “Citation and Teaching vs World Rank of Top 100 Universities” başlığı altında, dünya sıralaması (x ekseninde) ile atıf sayısı ve öğretim skoru (y ekseninde) arasındaki ilişkiyi gösteren iki çizgi grafiği çizdirilecektir. Her çizgi, farklı bir renkte olacak, ve fareyle her bir nokta üzerine gelindiğinde, o noktaya karşılık gelen üniversitenin adı görüntülenecektir.
#plt.style.use("ggplot")
# creating trace 1
trace1 = go.Scatter(
x = df.world_rank,
y = df.citations,
mode = "lines", # Bu dağılım izi için çizim modunu belirler. "mode=text" ise text'i yazdırır "text" öğeleri koordinatlarda görünür.
# Aksi takdirde, fareyle üzerine gelindiğinde "text" öğeleri görünür.
# 20'den az nokta varsa ve iz yığınlanmamışsa varsayılan değer "lines+markers"dir. Aksi takdirde, "lines".
name = "citations",
marker = dict(color = "rgb(16, 112, 2)"), # {"color" : "rgb(16, 112, 2)"}
text = df.university_name)
# creating trace 2
trace2 = go.Scatter(
x = df.world_rank,
y = df.teaching,
mode = "lines + markers",
name = "teaching",
marker = dict(color = "rgb(80,26,80)",
size = 10,
symbol = "star",
line = dict(
color = "yellow",
width = 1),),
text = df.university_name)
data = [trace1, trace2]
layout = dict(title = "Citation and Teaching vs Work Rank of Top 100 Universities", #axes olarak düşünebiliriz
xaxis = dict(title = "World Rank", ticklen = 5, tickcolor = "crimson", zeroline = False),
yaxis = dict(title = "Value", ticklen = 5, tickcolor = "crimson", zeroline = False))
fig = dict(data = data, layout = layout) #figure içine yukarıda tanımladığımız grafik değişkenlerini ve layout parametrelerini dict olarak verip
iplot(fig) #iplot(fig) ile çizdiriyoruz.
Scatter Plot
Scatter plot (saçılım grafiği), iki değişken arasındaki ilişkiyi, veri dağılımını ve veri gruplarını görsel olarak ayırt etmek için kullanılan bir grafik türüdür.
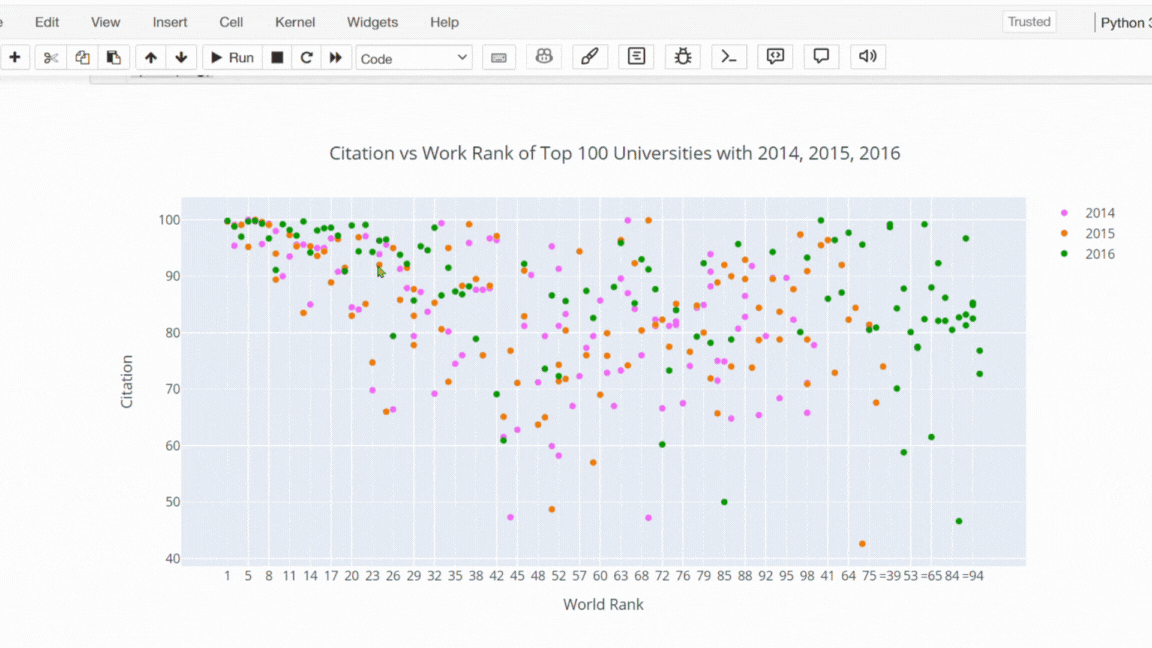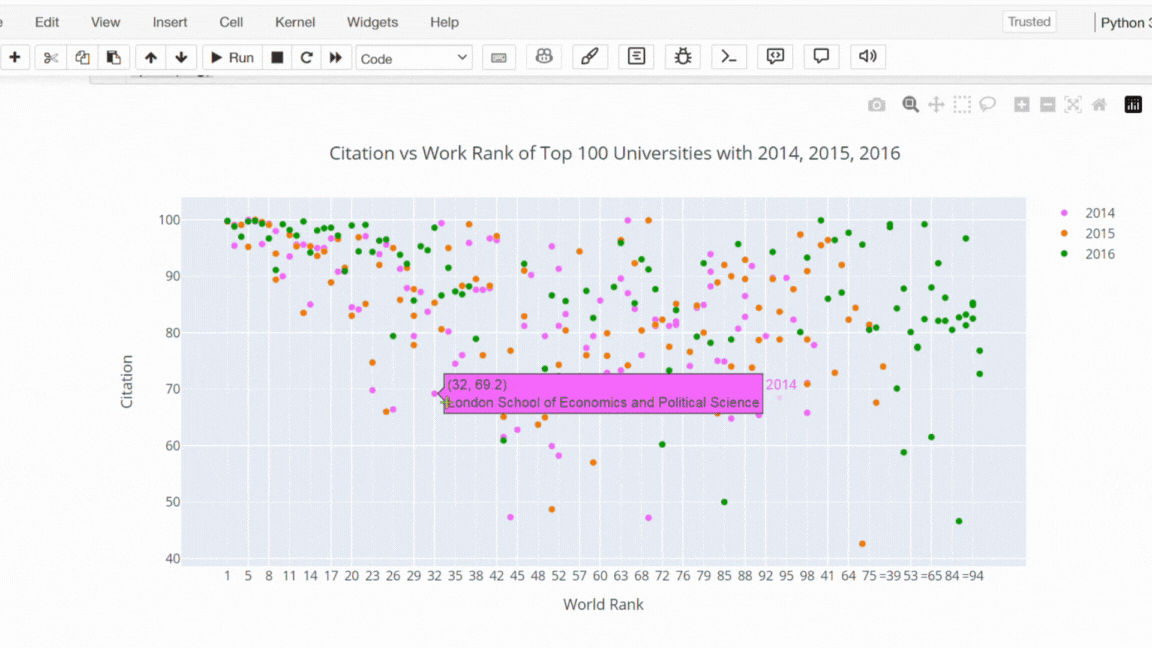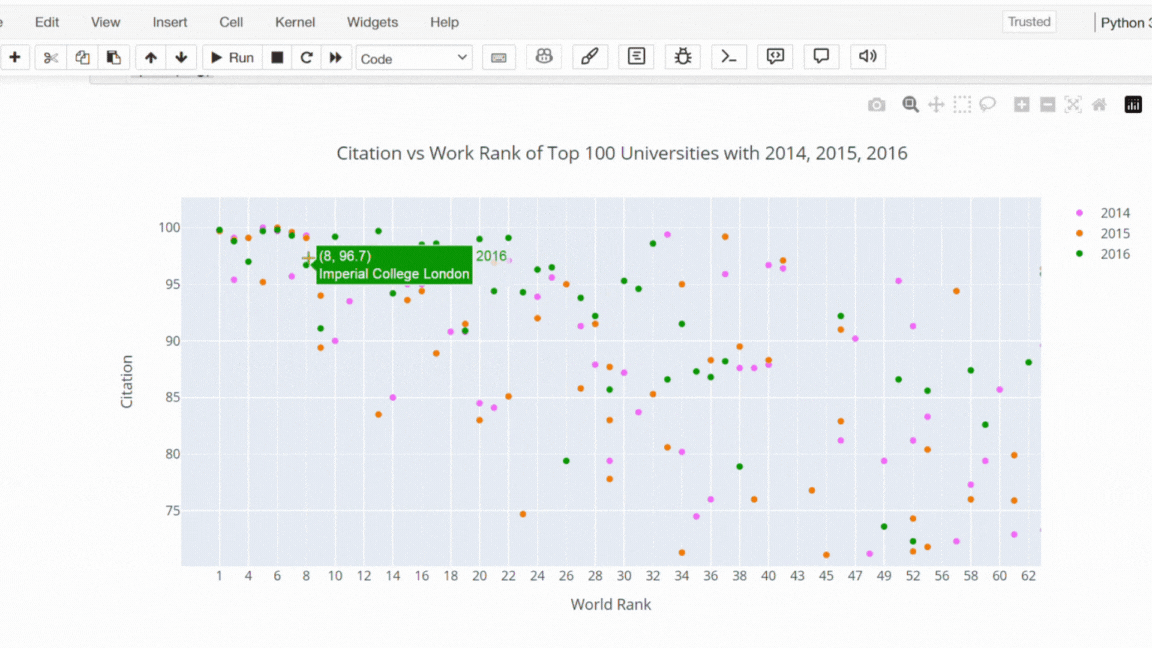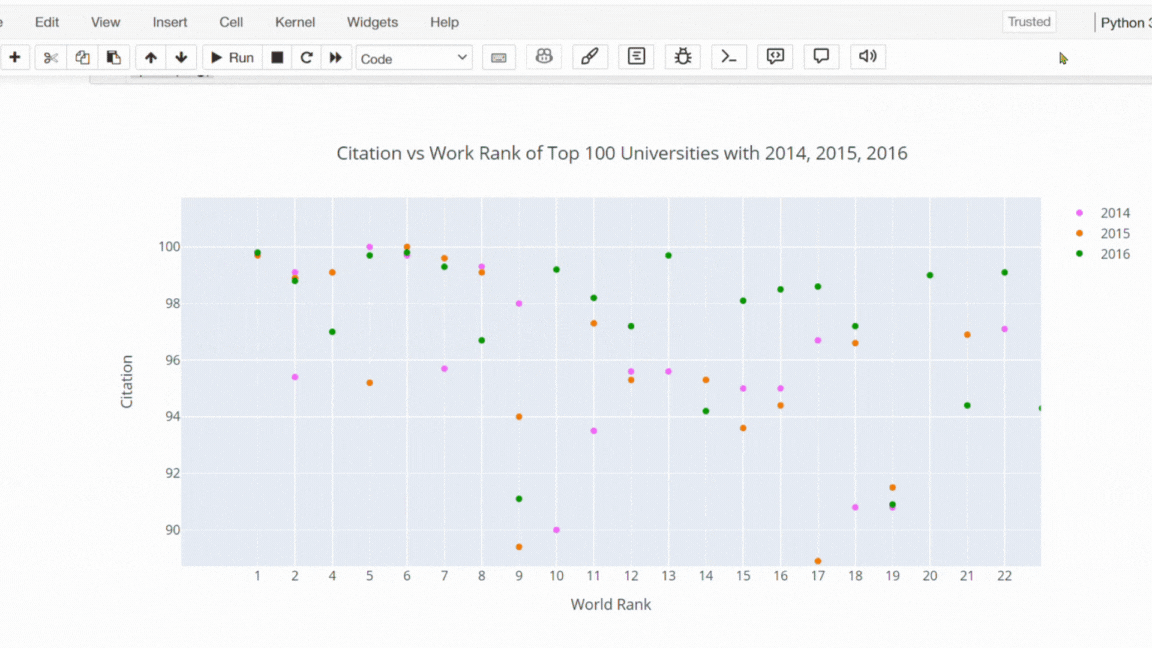
Şimdi plotly ile bir scatter plot çizdirelim. Bu kod parçası ile 2014, 2015 ve 2016 yıllarında ilk 100 üniversitenin citation (atıf) sayılarına karşı dünya sıralamalarını bir scatter plot ile görselleştirilmesi hedeflenmiştir.
# Filtering the data to include the top 100 universities' citation counts for the years 2014, 2015, and 2016.
df2014 = timesData[timesData.year == 2014].iloc[:100,:]
df2015 = timesData[timesData.year == 2015].iloc[:100,:]
df2016 = timesData[timesData.year == 2016].iloc[:100,:]
# creating trace 1
trace1 = go.Scatter(
x = df2014.world_rank,
y = df2014.citations,
mode = "markers",
name = "2014",
marker = dict(color = "rgb(255,128,255)"),
text = df2014.university_name)
# creating trace 2
trace2 = go.Scatter(
x = df2015.world_rank,
y = df2015.citations,
mode = "markers",
name = "2015",
marker = dict(color = "rgb(255,128,2)"),
text = df2015.university_name)
# creating trace 3
trace3 = go.Scatter(
x = df2016.world_rank,
y = df2016.citations,
mode = "markers",
name = "2016",
marker = dict(color = "green"),
text = df2016.university_name)
data = [trace1, trace2, trace3]
layout = dict(title = "Citation vs Work Rank of Top 100 Universities with 2014, 2015, 2016",title_x = 0.5, title_y = 0.9,
xaxis = dict(title = "World Rank"),
yaxis = dict(title = "Citation"))
fig = dict(data = data, layout = layout)
iplot(fig)